Hospital "Fingerprint" Helps AI Identify Misdiagnoses in Cancer Tissue
The origin of a sample must not influence the result: Evaluation criteria for trustworthy clinical AI

A new study by BIFOLD researchers at TU Berlin, in collaboration with the Berlin-based AI company Aignostics, Ludwig Maximilian University (LMU) in Munich, and the Netherlands cancer Institute (NKI), shows that today’s AI models for pathology can often be influenced simply by the hospital from which the tissue sample being examined originates. The team developed “PathoROB,” the world’s first evaluation metric designed to measure and mitigate this problem. PathoROB is already in widespread use and is thus shaping the next generation of AI models for pathology. The study has now been published in *Nature Communications*.
Artificial intelligence is intended to help doctors diagnose and characterize cancer more quickly and accurately. So-called foundation models—large AI systems pre-trained on millions of microscopic tissue images—are increasingly being used for cancer detection, disease classification, and biomarker prediction in clinical workflows. The new study by the interdisciplinary research team now reveals a critical weakness in these models: Every pathology lab leaves a subtle signature on its tissue sections—differences in the preparation, staining, and digitization of biopsies. These differences are medically irrelevant, but they are visible to AI systems, and the models internalize them. The researchers demonstrated that current foundation models can identify the hospital of origin of a tissue section with an accuracy of 88 to 98 percent based on their learned feature representations. In some cases, a model’s internal “map” of the data was organized primarily by hospital and only secondarily by whether the tissue was healthy or cancerous.
Hidden Hospital “Fingerprints” in the Models
The consequences can be serious. In one particularly striking example, an AI model learned to use the hospital signature as a shortcut for its decisions. As a result, it incorrectly classified a clearly malignant tissue sample as healthy—solely because the sample came from a hospital that had historically sent almost exclusively healthy samples and which the model had therefore associated with healthy tissue.
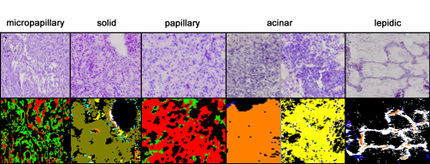
To quantify this problem, the researchers developed PathoROB, the first publicly available evaluation metric specifically designed to assess the robustness of foundation models in pathology against technical variations. It combines four datasets containing approximately 100,000 tissue sections, 28 biological classes, and 34 medical centers. In addition, it introduces a new “robustness index” that quantifies the extent to which a model’s internal representation is determined by biology rather than by hospital artifacts.
When applied to 20 widely used foundation models, PathoROB identified shortcomings in every single model. Larger models trained on more diverse data, as well as models that combine image data with text reports (vision-language models), achieved the best results. The researchers also tested various post-processing methods for “robustification” and found that these can significantly reduce the risk of such errors—though not entirely. This does not require costly retraining of the underlying model.
“Foundation models for pathology are evolving rapidly, and that’s extremely exciting. However, our results show that strong performance on a standard benchmark is not enough to trust a model in clinical use,” says Julius Hense, co-first author of the study and a researcher at BIFOLD and TU Berlin. “PathoROB provides developers and clinical users with a tool to verify whether a model has actually learned biological relationships or has merely recognized which hospital a specimen comes from.”
Shaping the Next Generation of Pathology AI
PathoROB is already changing the way AI for pathology is developed and evaluated. Aignostics’ next-generation foundation model, “Atlas 2,” developed in collaboration with the Mayo Clinic in the U.S., was specifically designed to address the trade-offs between performance and robustness identified by PathoROB. Furthermore, PathoROB is increasingly establishing itself as the gold standard for evaluating the robustness of foundation models. New models and platforms such as “Histoboard” now present their PathoROB results as one of the evaluation metrics to directly compare pathology AI models with one another.
By making the evaluation metric, the datasets, and the source code, the researchers hope to establish robustness evaluation as an integral part of the validation of biomedical foundation models—before these are used to support clinical decisions and thus potentially influence patient treatments.
Note: This article has been translated using a computer system without human intervention. LUMITOS offers these automatic translations to present a wider range of current news. Since this article has been translated with automatic translation, it is possible that it contains errors in vocabulary, syntax or grammar. The original article in German can be found here.
Original publication
Other news from the department science


























































